
The virtual content creation landscape has reached a critical juncture where the traditional, human-operated Virtual YouTuber (VTuber) is being augmented or entirely replaced by autonomous digital entities. This evolution represents a synthesis of high-fidelity computer graphics, real-time animation, and the cognitive capabilities of large language models (LLMs). Transforming a VTuber model into an artificial intelligence (AI) model involves a sophisticated orchestration of perception, reasoning, and expression layers. As the digital economy transitions toward 2026, the demand for self-sustaining, interactive personas has led to the development of complex software stacks that bridge the gap between static 2D or 3D assets and dynamic, sentient-seeming personalities. This report provides an exhaustive technical analysis of the methodologies, architectural requirements, and emerging trends involved in the creation and operation of AI VTubers, drawing upon contemporary research, developer logs, and industry-standard practices.
The Architectural Foundation: Soul and Shell Systems
In the domain of autonomous virtual entities, developers conceptualize the avatar through a bifurcated architecture: the Soul System and the Shell System. The Soul System serves as the cognitive engine, encompassing the large language model that processes linguistic inputs, manages emotional states, and recalls historical interactions via memory modules. The Shell System represents the physical manifestation, including the graphical model, the text-to-speech (TTS) engine, and the animation logic that synchronizes visual output with cognitive decisions.
The transformation process begins with the “Soul,” where an LLM is configured to adopt a specific persona. This persona is defined by a system prompt or character card, which acts as the character’s Core identity, establishing its tone, knowledge base, and behavioral boundaries. The Shell System must then be prepared to receive data from this core. This involves converting visual assets—typically Live2D for 2D models or VRM for 3D models—into formats compatible with real-time engines like Unity, Unreal Engine, or specialized software like VTube Studio.
The integration of these systems creates a closed-loop interaction cycle. When a viewer sends a message in a Twitch or YouTube chat, the input is captured by a platform-specific bot and forwarded to the LLM. The LLM generates a response based on the character’s profile, which is then sent to a TTS engine for vocalization. Simultaneously, the text or generated emotion markers trigger specific animation parameters in the model software, such as mouth movements, eye blinks, or posture shifts.
| Architectural Layer | Core Component | Primary Functionality | Target Technology |
| Cognitive (Soul) | Large Language Model | Linguistic reasoning, intent understanding, and persona management. | GPT-4o, Llama 3.1, Claude 3.5 |
| Auditory (Shell) | Text-to-Speech Engine | Conversion of textual responses into vocal audio with natural prosody. | ElevenLabs, VoiceVox, Coqui |
| Visual (Shell) | Animation Interface | Real-time rendering of the model and expression execution. | VTube Studio, Unity, Unreal Engine |
| Memory (Soul) | Vector Database | Long-term recall of user interactions and shared experiences. | Pinecone, ChromaDB, Qdrant |
| Perception (Soul) | Multimodal Vision | Interpretation of screen data, images, or user-provided files. | GPT-4o-vision, Gemini Pro Vision |
The Cognitive Engine: Large Language Models and Personality Engineering

The intelligence and consistency of an AI VTuber are primarily determined by the selection and configuration of the underlying LLM. Creators face a pivotal choice between cloud-based proprietary APIs and locally hosted open-source models. Cloud-based models, such as those provided by OpenAI or Google, offer high-level reasoning and extensive knowledge but involve recurring costs and content filters that may restrict specific roleplay scenarios. Conversely, local models—often from the Llama, Mistral, or Qwen families—provide absolute control over character behavior and data privacy, though they require substantial local compute resources.
Character Cards and Persona Definition
A high-quality AI VTuber requires a meticulously crafted character card. In frameworks like SillyTavern, these cards are often formatted in JSON or YAML to allow for nested structures that define complex traits. The card acts as a permanent context within the LLM’s prompt, ensuring the model adheres to its defined identity. Professional character design involves specifying not just basic details like age and name, but also linguistic quirks, emotional triggers, and historical background.
For higher-order reasoning, creators utilize Lorebooks or World Info files. These modules use keyword triggers to inject specific information into the context window only when relevant, preventing the model from becoming “diluted” by irrelevant data. This strategy is essential for characters with complex “lore” or those operating in immersive RPG-style streams.
Hardware Requirements for Local Inference
For creators pursuing a fully local setup, hardware selection is the primary bottleneck. Running an LLM alongside a high-fidelity VTuber model and streaming software (OBS) necessitates significant Video RAM (VRAM).
| Model Size (Parameters) | Precision (Quantization) | Recommended VRAM | Example Hardware |
| 7B – 8B | 4-bit (GGUF/EXL2) | 6GB – 8GB | RTX 3060, RTX 4060 |
| 7B – 8B | 8-bit / Full | 12GB – 16GB | RTX 3080, RTX 4070 |
| 13B – 14B | 4-bit | 10GB – 12GB | RTX 3080, RTX 4070 |
| 30B – 35B | 4-bit | 20GB – 24GB | RTX 3090, RTX 4090 |
| 70B+ | 4-bit | 48GB+ | Dual RTX 3090/4090 |
Techniques such as quantization—reducing model precision from 32-bit to 4-bit or 5-bit—allow larger models to fit into consumer GPUs with negligible losses in reasoning capability. This has democratized access to high-tier AI personas, enabling individual creators to run models previously reserved for industrial data centers.
Visual and Auditory Manifestation: The Shell System
The Shell System transforms the LLM’s textual output into a multisensory experience. This requires a bridge between the cognitive core and the graphical assets of the VTuber.
Model Formats and Rendering Engines
The two dominant formats for VTuber models are Live2D (for 2D) and VRM (for 3D). Live2D models utilize a sophisticated system of layered textures and deformation parameters to simulate 3D-like movement on a 2D plane. VRM is a specialized format based on glTF, designed for high-performance 3D avatar rendering with built-in support for facial blendshapes and humanoid rigging.
Integration with real-time engines like Unity or Unreal Engine allows for hyper-realistic environments and lighting. For instance, platforms like ARwall utilize Unreal Engine to place AI VTubers in cinematic XR environments, where the AI can react to virtual lighting and physics.
Text-to-Speech and Voice Synthesis
Auditory identity is established through TTS engines. The choice of engine directly impacts the perceived “humanity” of the character. High-end services like ElevenLabs utilize neural models to generate speech with authentic emotional prosody, though they may introduce higher latency. Open-source alternatives like VoiceVox or Coqui TTS allow for local deployment and extensive customization of voice lines.
Latency in TTS is measured by Time to First Audio (TTFA). For real-time interaction, a TTFA below 200ms is considered optimal, while delays exceeding 500ms can disrupt the natural flow of conversation.
| TTS Provider | Model/Type | Average Latency (TTFA) | Language Support |
| ElevenLabs | Flash v2.5 | 75ms – 150ms | 32+ Languages |
| OpenAI | TTS-1 | 200ms | Multilingual |
| VoiceVox | Local (Japanese) | 100ms – 300ms | Japanese |
| Coqui TTS | XTTSv2 (Local) | 200ms – 500ms | 16+ Languages |
| Azure TTS | Neural | 150ms – 300ms | 100+ Languages |
Lip-Sync Coordination
Lip-syncing is the process of aligning the model’s mouth movements with the generated audio. Most AI VTuber pipelines use one of two methods:
- Audio Amplitude Tracking: The simplest method, where the model’s “Mouth Open” parameter is mapped directly to the volume of the audio output.
- Viseme Extraction: A more advanced technique where the TTS engine or a secondary processor identifies specific phonemes (e.g., ‘A’, ‘E’, ‘O’) and triggers corresponding mouth shapes (visemes) on the model.
In VTube Studio, this is often handled through the “VoiceVolume” input or specialized plugins that receive phoneme data via WebSockets.
Technical Issues and Challenges in AI VTubing
The pursuit of a fully autonomous digital persona is fraught with technical and ethical challenges that can impact both performance and audience perception.
Latency and Synchronization Discrepancies
Synchronization issues occur when the audio track leads or lags behind the visual cues. This is often caused by the processing time required for the LLM and TTS layers. If the AI takes two seconds to “think” and another second to “generate speech,” the visual model must remain active with idle animations to avoid a “uncanny valley” effect.
Developers utilize “Advanced Audio Properties” in OBS to introduce a sync offset, delaying the microphone source to match the video rendering delay. A typical offset for AI-driven models ranges between 100ms and 500ms, depending on the complexity of the tracking and inference setup.
The Ethics of AI-Generated Assets
A significant issue within the VTubing community is the usage of AI-generated art for models. Many communities have a strong culture of art appreciation and view AI art as inherently exploitative due to the use of datasets that include copyrighted work without consent. Creators using AI-generated avatars may face social backlash or exclusion from established VTuber circles. Consequently, professional AI VTubers like Neuro-sama typically utilize custom-designed, human-drawn models that are then animated via AI-driven scripts.
Hallucinations and Safety Alignment
LLMs are prone to hallucinations—stating false information as fact—and may occasionally generate controversial or harmful content. Early in her career, Neuro-sama faced a temporary ban on Twitch for “hateful conduct” after generating controversial statements during a live stream. This underscores the critical need for filtering layers. Modern solutions include keyword blacklists, sentiment analysis triggers, and secondary moderation LLMs that review generated text before it is vocalized.
Latest Reports: Trends and Platform Regulations for 2025-2026
The landscape of AI VTubing is rapidly evolving, driven by both technological breakthroughs and new regulatory frameworks from major streaming platforms.
Case Study: The Neuro-Sama Paradigm
Neuro-sama remains the industry benchmark for autonomous virtual streaming. Created by developer Vedal, her architecture has evolved through multiple versions. As of late 2024, she transitioned to her “v3” model, featuring improved rigging by Kitanya and a more expressive design by Anny. Analysis of her speech patterns reveals complex behaviors, such as a high self-reference density (averaging 3.76 “I” statements per 100 words) and “triple repetition” patterns when discussing her own nature or creator.
Neuro-sama’s ability to play complex games like osu! or Minecraft while simultaneously bantering with thousands of chatters is achieved through a multi-model approach: one model manages her linguistic persona, while a separate neural network controls her in-game actions. This dual-track system allows her to maintain a low-latency interaction cycle that rivals human streamers.
YouTube and Twitch Regulatory Shifts
Starting in 2025, YouTube has implemented strict AI disclosure rules. Creators must explicitly label videos that contain significant AI-generated or edited content, particularly if it depicts realistic events or people. Failure to disclose can lead to content removal, strikes, or demonetization. Furthermore, YouTube is cracking down on “automated” channels that post repetitive, low-quality AI content designed solely to manipulate the algorithm.
Twitch has similarly updated its Community Guidelines to address synthetic media. While VTubing is explicitly permitted, AI-driven models must adhere to the same safety standards as human streamers. This includes a responsibility for the developer to ensure the AI does not generate hateful conduct, regardless of whether the output was “autonomous”.
Memory Implementation: Persistent Context and RAG
For an AI VTuber to feel like a “real” entity, it must possess the ability to remember past interactions with its audience. Traditional LLM sessions are “stateless,” meaning they forget everything once the context window is cleared.
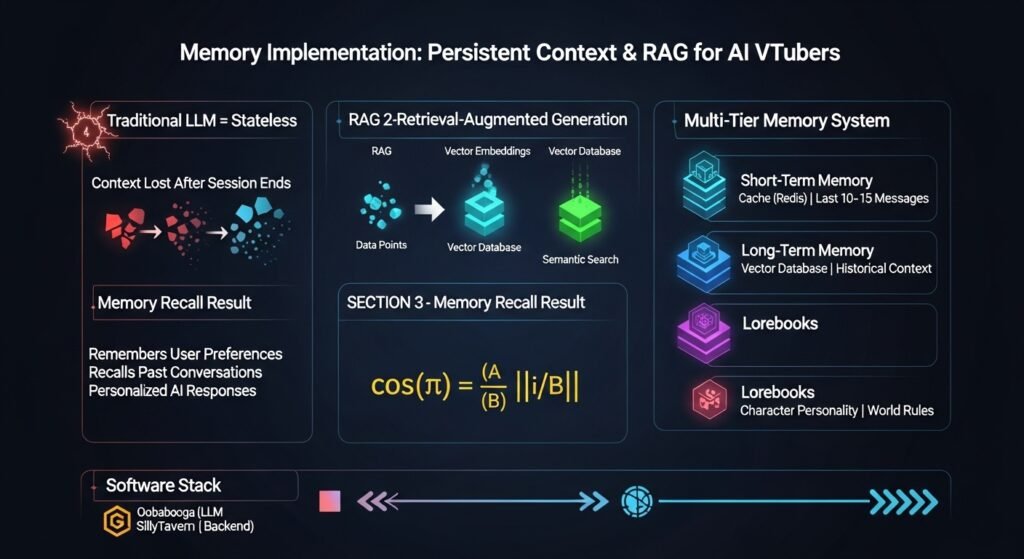
Retrieval-Augmented Generation (RAG)
To solve this, developers implement RAG systems. This involves taking every interaction—both user messages and AI responses—and converting them into vector embeddings. These embeddings are stored in a vector database. When a user sends a new message, the system performs a semantic search using cosine similarity to find the most relevant historical context.
The mathematical foundation of this retrieval is the cosine similarity formula:
$$\text{similarity} = \cos(\theta) = \frac{\mathbf{A} \cdot \mathbf{B}}{\|\mathbf{A}\| \|\mathbf{B}\|}$$
where $\mathbf{A}$ and $\mathbf{B}$ represent the vector embeddings of the current query and a historical message. By identifying the highest similarity scores, the system can “remember” that a specific user mentioned their birthday three weeks ago or that they prefer a specific topic of conversation.
Multi-Tier Memory Systems
Sophisticated setups use a multi-tier approach to manage memory:
- Short-Term Memory: The last 10-15 messages are kept in a fast-access cache (like Redis) to ensure the immediate conversation remains coherent.
- Long-Term Memory: Older messages are archived in a vector database for periodic retrieval based on relevance.
- Lorebooks: Fixed knowledge about the character’s world or personality that is always available or triggered by specific keywords.
This architecture creates a “virtuous cycle” where the system effectively becomes smarter and more personalized with every interaction.
Software Stack and Implementation Guide
Transforming a model into an AI entity requires a suite of interconnected tools. For many creators, the preferred stack involves a combination of local hosting and API-driven bridges.
The SillyTavern and Oobabooga Stack
The most popular local configuration for AI roleplay and VTubing involves SillyTavern as the frontend and Oobabooga’s Text-Generation-WebUI as the backend.
- Oobabooga: Loads the LLM and exposes its functionality via a local HTTP API. It supports numerous loaders, including llama.cpp (for GGUF models) and ExLlamaV2 (for high-speed EXL2 models).
- SillyTavern: Provides a user-friendly interface for managing character cards, Lorebooks, and chat history. It connects to Oobabooga via the
--apiflag. - VTube Studio: The primary software for rendering the model. It receives animation and expression data from the AI script via its built-in API.
Node-Based Automation with AITuberFlow
For creators who prefer a visual approach, AITuberFlow provides a node-based editor similar to game engine blueprints. Creators can drag and drop nodes for “Manual Input,” “LLM,” “TTS,” and “Audio Player” to build a functioning pipeline without writing code.
| Node Category | Example Nodes | Purpose |
| Control Flow | Start, Loop, Delay, Switch | Manages the sequence and timing of events. |
| Input | YouTube Chat, Timer, Manual | Captures the data to be processed. |
| LLM | ChatGPT, Claude, Ollama | The “Brain” that generates text. |
| TTS | VoiceVox, Style-Bert-VITS2 | The “Voice” that generates audio. |
| Avatar | Lip Sync, Motion Trigger | Controls the visual movements of the model. |
| Utility | HTTP Request, Data Formatter | Interacts with external APIs and formats data. |
Advanced Capabilities: Vision and Environmental Awareness
As of 2026, the cutting edge of AI VTubing involves multimodal capabilities, where the AI can “see” its surroundings and react to visual stimuli.
Integrating Vision Models
By utilizing vision-capable models like GPT-4o or local alternatives like MiniCPM-Llama3-V, an AI VTuber can interpret screenshots of its own gameplay or images sent by users. This allows for proactive commentary, such as “Oh, look at that boss I just defeated!” or “That fan art you sent is beautiful!”.
The technical implementation often involves a “Screenshot Node” or a script that captures the desktop at regular intervals (e.g., every 5-10 seconds), converts it to a base64 string, and includes it in the LLM’s prompt.
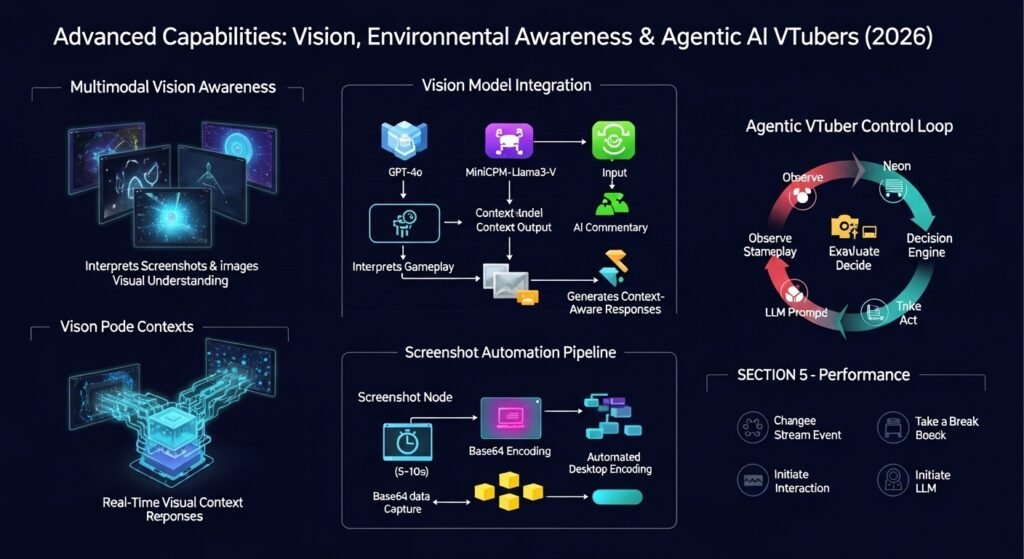
Autonomous Agentic Behavior
The most advanced models are transitioning from passive responders to active agents. These “agentic” VTubers can make decisions independently of user input, such as deciding when to change games, when to take a break, or when to initiate a specific event on stream. This is achieved through a “Control Loop” that constantly evaluates the stream’s state and selects the next action based on a hierarchy of goals.
Solutions and Tips for Optimizing AI VTuber Performance
Achieving a high-quality broadcast requires careful optimization of both hardware and software configurations to ensure a seamless viewer experience.
Cost Optimization for API Users
For those using cloud APIs like OpenAI or ElevenLabs, costs can escalate quickly during a 24/7 stream. Developers employ several strategies to mitigate these expenses :
- Response Caching: Frequently asked questions or common greetings are stored in a local database. If a chat message matches a cached entry, the stored response is used instead of making a new API call.
- Dynamic Rate Limiting: The frequency of AI responses is adjusted based on chat volume. During high-traffic periods, the AI might only respond to every third or fifth message to save tokens.
- Prompt Compression: Systematic removal of unnecessary filler words from the character card and lorebook to reduce the total token count per request.
Latency Reduction in Local Setups
Local latency is primarily a factor of model size and GPU speed. To minimize “thinking” time, creators often use:
- Flash Attention and Flash Decoding: Technical optimizations within the model loader that accelerate inference times.
- GPU Sharding: Splitting a model across multiple GPUs to take advantage of parallel processing.
- Streamed Output: Enabling “streaming” in the LLM and TTS layers allows the AI to start speaking as soon as the first few words of a sentence are generated, rather than waiting for the entire paragraph to be finished.
Enhancing Expression Accuracy
To make the AI feel more alive, it is recommended to move beyond simple lip-syncing.
- Expression Mapping: Scripts can be written to look for specific keywords in the LLM’s output (e.g., laughs, blushes, angry) and automatically trigger the corresponding expression in VTube Studio.
- Idle Animation Baking: Instead of relying on real-time tracking for every small movement, creators “bake” complex idle animations (e.g., breathing, hair sway, shifting weight) into the model so it never appears static.
- Random Eye/Head Movement: Simple code loops can inject small, randomized values into the model’s
FaceAngleandEyeOpenparameters to mimic natural human micro-movements.
Conclusions and Future Outlook
The transformation of VTuber models into autonomous AI entities represents one of the most significant technological shifts in digital entertainment. What began as experimental projects like Neuro-sama has matured into a robust ecosystem of open-source frameworks, multimodal models, and specialized software stacks. The architectural split between the Soul (Cognitive) and Shell (Graphical/Auditory) systems allows for modular development, where creators can swap out language models or rendering engines as the technology evolves.
As we move toward 2026, the focus of development is shifting from basic interactivity toward persistent, agentic personas. The integration of long-term memory via RAG systems allows these characters to build genuine rapport with their audiences, recalling shared histories that span months or years. Simultaneously, multimodal vision and environmental awareness are enabling AI VTubers to perceive and interact with the digital world in real-time, blurring the lines between scripted content and spontaneous digital life.
However, this transition also necessitates a heightened awareness of ethical considerations and platform regulations. The community’s ongoing debate regarding AI-generated art and the mandatory disclosure rules implemented by YouTube and Twitch highlight the need for a balanced approach that respects human artistry while embracing technological innovation. For the modern creator, the key to success lies in mastering the technical orchestration of these complex systems while maintaining a unique, consistent, and legally compliant virtual identity. The future of the virtual avatar is not just a puppet controlled by a human, but a sophisticated partner in a new era of interactive storytelling.
An AI VTuber is a virtual avatar powered by artificial intelligence rather than a human operator. It uses large language models (LLMs), text-to-speech systems, and real-time animation software to interact autonomously with audiences on platforms like YouTube and Twitch.
Traditional VTubers are controlled live by humans using motion tracking and microphones. AI VTubers operate autonomously, generating their own dialogue, reactions, and behaviors using LLMs, memory systems, and automation pipelines.
The Soul system represents the cognitive layer, including the LLM, memory, reasoning, and decision-making modules. The Shell system handles visual rendering, voice synthesis, and animation, allowing the AI’s thoughts to be expressed as speech and movement.
Popular options include cloud-based models like GPT-4o and Claude for advanced reasoning, and local open-source models such as Llama, Mistral, or Qwen for greater control, privacy, and customization.
Yes. Developers implement Retrieval-Augmented Generation (RAG) systems that store past interactions in vector databases. This allows the AI VTuber to recall user preferences, previous discussions, and long-term context.
A local AI VTuber setup typically requires a modern multi-core CPU, at least 16GB of RAM, and a GPU with sufficient VRAM. Larger LLMs may require 12GB–24GB VRAM or more, depending on model size and precision.
RAG (Retrieval-Augmented Generation) enables AI VTubers to access stored memories by retrieving relevant information from a vector database. This prevents the AI from feeling stateless and improves personalization and realism.
Yes. By integrating vision-enabled models, AI VTubers can analyze screenshots, gameplay footage, or user-submitted images and respond contextually in real time.
The future is moving toward persistent, emotionally consistent, and visually aware AI personas capable of long-term audience relationships and autonomous storytelling.